

Pengarang: Tim Cvetko
Karir
Hal-hal yang harus diperhatikan selama Masalah DS Anda
Pekerjaan paling seksi di dunia abad ke-21 mungkin menarik tetapi juga disertai dengan banyak tantangan. Jangan khawatir. Ini adalah hari keberuntungan Anda!!!
Saya mempersembahkan kepada Anda buku panduan ilmu data ujung-ke-ujung yang modern. Mudah-mudahan, setelah membaca artikel ini Anda dapat menyalakan bola lampu kecil di belakang kepala Anda setiap kali Anda menghadapi tantangan di dunia AI.

Memahami Masalah
Sebagai peneliti, programmer, dan ‘smart creatives’, kami terbawa oleh hasil dan sensasi kecerdasan buatan dan kemampuannya. Kami ingin mendapatkan hasil dan kami ingin mereka cepat.
Duduk, bernapas, ambil selembar kertas dan pena dan mulailah membuat sketsa.
Brainstorming, jika perlu. Membuat rencana. Saya ingin Anda merangkul mentalitas berpikir 3 langkah ke depan. Sebelum kode yang menarik [ML] dimulai, saya ingin Anda memikirkan:
1 -> alat apa yang akan Anda gunakan untuk saluran data Anda,
2 -> apakah akan ada overhead dalam data (bola lampu harus mati: generator Python, pipa Spark)
3 -> format data apa yang akan saya gunakan, bagaimana ini kompatibel dengan yang saya butuhkan untuk pelatihan?
4 -> apakah masalah saya benar-benar mendapatkan solusi ML?
Selalu pikirkan yang lebih mudah [non ML] larutan.
Saya jamin Anda: Ketika Anda menemukannya, Anda akan menemukan wawasan yang tidak akan Anda miliki sebaliknya. Anda akan melihat masalah Anda dari perspektif yang berbeda. Bahkan jika solusi Anda memang membutuhkan solusi ML, Anda akan mendapat manfaat yang luar biasa.
Mengapa mengetahui masalah adalah arus utama proyek?
Anda tidak dapat memahami data jika Anda tidak memahami masalahnya Anda harus memiliki narasi sepanjang proses dan Anda harus berusaha sedekat mungkin untuk menemukan solusinya. Tindakan Anda sebaliknya tanpa tujuan. Ingat, algoritma berputar di sekitar masalah, bukan sebaliknya. Anda tidak boleh melihat algoritme dan membayangkan atau bahkan memaksanya untuk menyelesaikan tugas. Misalnya: memecahkan masalah jalur terpendek harus memicu bola lampu itu: “Dijkstra”.
Langkah Selanjutnya adalah memilih Pendekatan
Setelah cukup lama di dunia ML, Anda akan dapat membayangkan solusi sebelum menerima data. Meskipun kedengarannya bagus, tidak.
Inilah alasannya: alasan mengapa Anda begitu hebat dalam apa yang Anda lakukan, adalah karena Anda mampu berpikir di luar jangkauan pengetahuan Anda. Sebagai ilmuwan data modern, tugas Anda adalah menemukan solusi cerdas untuk masalah modern. Kami mungkin juga mengalihkan fokus kami ke AutoML jika itu tidak terjadi.
Ingat motto sebelumnya: Masalah Pertama, Algoritma, dan Solusi Nanti? Tambahkan ini: “Lebih sering daripada tidak, lebih mudah untuk mendelegasikan tugas Anda. “
Pecahkan masalah Anda. Lihat gambaran besarnya.
Pada titik ini, saya ingin Anda menggali lebih dalam keahlian Anda dalam algoritme dan teknik matematika. Berpikirlah seperti pengembang ujung ke ujung sejak awal. Antisipasi hal-hal yang tidak terduga. Dengan asumsi Anda memahami jenis data yang Anda hadapi dan jenis masalah yang Anda coba pecahkan. Jarang sekali algoritma satu jenis berfungsi.
Saat meneliti, pikirkan di mana setiap algoritme mungkin salah. Jika Anda berurusan dengan jaringan saraf, saya ingin Anda memikirkan tentang gradien, memilih pengoptimal yang tepat, efek apa yang mungkin ditimbulkan oleh regularisasi, dll. Anda harus menjadi orang yang tidak tahu apa-apa, bukan TensorFlow.
pembelajaran langsung adalah jenis pembelajaran terbaik
Sebagai contoh:
Stochastic Gradient Descent memiliki konvergensi yang lebih ribut daripada Adam. Salah satu keuntungan menggunakan sparse categorical cross-entropy adalah menghemat waktu dalam memori serta komputasi karena menggunakan integer tunggal untuk kelas, daripada seluruh vektor. Ini adalah jenis bola lampu yang saya bicarakan.

Catatan: begitu data dapat dikelola, saat itulah keajaiban dimulai. Pada tahap itu, Anda tentu saja dapat mencoba berbagai pendekatan, melakukan penyetelan hyperparameter, dan sebagainya.
Memahami Data Anda -> EDA
EDA adalah singkatan dari analisis data eksplorasi dan mungkin merupakan bagian terpenting dari perjalanan proyek DS Anda. Tidak ada proyek dunia nyata yang bergantung pada data murni. Anda akan menghabiskan banyak waktu untuk pengambilan dan manipulasi data.
“Semua orang ingin melakukan pekerjaan model, bukan pekerjaan data”: Data Cascades dalam AI Taruhan Tinggi — Google Research
Proyek ini berkisar pada tujuan Anda. Carilah makna tersembunyi dalam data, korespondensi mereka. Jangan meremehkan kekuatan visualisasi data. Sebagai pemrogram, kami menjadi cukup arogan tentang visualisasi data karena ini menunjukkan bahwa kami tidak memahami data kami. Jangan biarkan ego itu menguasai Anda.
Pergi lebih dalam. Temukan setiap wawasan yang mungkin.
Rekayasa fitur adalah proses menggunakan pengetahuan domain untuk mengekstrak fitur dari data mentah melalui teknik data mining. Fitur-fitur ini dapat digunakan untuk meningkatkan kinerja algoritma pembelajaran mesin.
Pada titik ini, saya ingin menunjukkan kepada Anda sekumpulan trik yang berguna untuk memilih fitur:
persilangan fitur -> contoh persilangan fitur yang paling terkenal adalah masalah garis bujur-lintang. Kedua nilai ini bisa jadi hanyalah nilai mengambang yang sepi dalam kumpulan data. Jika Anda memilih untuk mengejar pentingnya lokasi, tujuan akhirnya adalah untuk menentukan wilayah mana yang memiliki korespondensi tertinggi terhadap output. Kombinasi persilangan fitur dapat memberikan kemampuan prediktif di luar apa yang dapat diberikan fitur tersebut secara individual.
Persilangan Fitur | Kursus Singkat Machine Learning | Pengembang Google
Kemungkinan lain untuk lokasi adalah untuk mendefinisikan kelompok titik data dan meneruskan labelnya ke model.
https://medium.com/media/0a84ed294f0b8441f79d216091076fe0/href
berurusan dengan nilai yang hilang (NaN)-> ini selalu merupakan masalah yang menjengkelkan, bukan? Langkah pertama: — temukan wawasan untuk kolom dengan data yang hilang dan hapus fitur tersebut dari persamaan. Kedua: Mungkin, ini memiliki korelasi yang tinggi dengan kolom lain dan kemudian Anda dapat menggunakan padding. Temukan lebih banyak di sini:
Padding dan Bekerja dengan Nilai Null atau Missing
Izinkan saya memberi Anda saran yang tidak mereka ajarkan di sekolah, guys. Jika kolom yang diinginkan tidak cocok dengan persyaratan sebelumnya dan Anda menemukan bahwa kolom tersebut memiliki korelasi yang rendah dengan output, hapus kolom tersebut.
normalisasi data -> sederhananya, ini adalah proses penskalaan data Anda sambil tetap mewakili apa yang seharusnya diwakilinya. Kenapa kamu ingin melakukan itu? Pertama, ini membantu dengan outlier. Kedua, sementara itu tidak memperbaiki masalah gradien yang meledak, itu bertahan lebih lama. Ketiga, memberikan distribusi yang lebih unik dari sebelumnya. berurusan dengan outlier-> outlier adalah elemen yang tidak mungkin dari dataset yang jauh dari batas yang diinginkan.
Cara Menghapus Pencilan untuk Pembelajaran Mesin – Penguasaan Pembelajaran Mesin
Kabar baik: Anda dapat memilih apa yang merupakan outlier pada data Anda dan apa yang akan Anda lakukan terhadapnya.
Interpretasi Model
Anda telah mencapai langkah terakhir proyek Anda. Namun, ini mungkin yang memperkuat Anda sebagai ilmuwan data. “Dia yang bercerita”, kan?
Sampai sejauh ini, Anda tidak ragu lagi akan mendorong model Anda hingga batas kemungkinannya. Kita semua sedang memikirkannya sekarang, jadi saya hanya akan mengatakannya: “Penyetelan hiperparameter”.
Saya telah membahas banyak detail tentang itu di artikel berikut, jadi lanjutkan.
Penyetelan Hyperparameter 101
Keynote: “Jangan menemukan kembali roda. Tidak perlu. Tujuannya adalah untuk memberikan hyperparameter terbaik untuk model Anda. “
Selain itu, saya ingin menambahkan sesuatu yang disebut juga sebagai metode Pandas vs Caviar. Ini masalah mengasuh seorang model dan menunggu hasilnya atau beralih ke beberapa model dan memilih yang terbaik.
Kaviar > Panda. Selalu.
Setiap proyek memiliki interpretasi metriknya sendiri. Agar berhasil, Anda harus berpikir di luar cakupan kepatuhan umum. Tanyakan pada diri Anda ini:
Kriteria apa yang akan membuat proyek/model ini berhasil?
Pada titik mana Anda dapat mengatakan bahwa Anda puas dengan kinerja model Anda?
Anda yang paling tahu model Anda, jadi sekali lagi, ini hanya beberapa trik:
akurasi plot / persentil kerugian (ini menunjukkan seberapa salah model Anda pada set pengujian, yaitu seberapa jauh prediksi Anda)
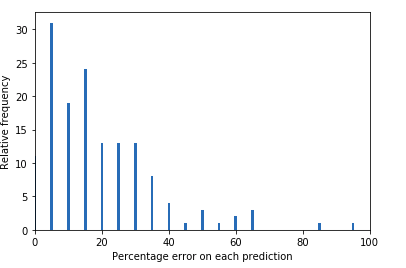 Gambar oleh Penulis melacak kehilangan dan akurasi (gunakan panggilan balik penghentian awal, regularisasi, atau TensorBoard untuk logging) temukan koneksi tersembunyi antara data yang salah prediksi, sehingga Anda dapat memperbaiki mengapa demikian
Gambar oleh Penulis melacak kehilangan dan akurasi (gunakan panggilan balik penghentian awal, regularisasi, atau TensorBoard untuk logging) temukan koneksi tersembunyi antara data yang salah prediksi, sehingga Anda dapat memperbaiki mengapa demikian
Terakhir, pikirkan tentang interaksi pelanggan/bisnis. Apa aplikasi model Anda?
Dapatkan posisi orang yang Anda coba jual kekuatan AI Anda dan pikirkan perjuangan yang mungkin mereka miliki. Persiapan seperti itu akan dicatat, percayalah.
Kesimpulan
Ini dia. Ini adalah buku panduan langkah demi langkah saya untuk Ilmu Data. Saya mendorong Anda untuk mengambil daftar ini sebelum Anda memulai proyek baru dan berpikir ke depan. Jika saya dapat menyimpulkan, saran terbesar saya untuk Anda adalah: Kenali apa yang Anda hadapi. Data benar-benar merupakan inti dari proyek Anda. Modelnya hanya bisa sebagus data Anda. Bersiaplah dan hasilnya tidak akan mengecewakan.
Rangkullah pola pikir seorang ilmuwan data modern. Dan ingat, ketika dalam posisi yang tampaknya tanpa harapan, kita semua pernah ke sana. Moto saya adalah jika tidak membutuhkan setidaknya 100 bug selama pengkodean, apa gunanya?
Hubungkan dan baca lebih lanjut
Jangan ragu untuk menghubungi saya melalui media sosial apa pun. Saya akan senang untuk mendapatkan umpan balik, pengakuan, atau kritik Anda.
LinkedIn, Medium, GitHub, Gmail
Saya baru saja mulai menulis buletin saya sendiri dan saya akan sangat menghargainya jika Anda memeriksanya.
Tautan: https://winning-pioneer-3527.ck.page/4ffcbd7ad7.
Buku Panduan Ilmu Data 2021 awalnya diterbitkan di Towards AI on Medium, di mana orang-orang melanjutkan percakapan dengan menyoroti dan menanggapi cerita ini.
Diterbitkan melalui Menuju AI