

Pengarang: mer zgür
Pengantar Ilmu Data Genom
 Dari https://www.bezelyedergi.net/post/biyoinformatik-sekanslama-teknolojileri
Dari https://www.bezelyedergi.net/post/biyoinformatik-sekanslama-teknolojileri
Setiap organisme hidup memiliki genom di jantungnya. Jika sel adalah komputer, urutan genom adalah perangkat lunak yang dijalankannya. Jika kita menganggap DNA sebagai perangkat lunak yang dijalankan oleh sel, kita dapat menggunakan komputer kita untuk menganalisisnya dengan logika yang sama. DNA bukan hanya gudang informasi.
Ini adalah struktur fisik yang dapat berperilaku dengan cara yang kompleks. Genom adalah mesin yang sangat kompleks yang terdiri dari ribuan bagian. Meskipun kita tahu bagaimana beberapa gen bekerja hari ini, tidak dipahami berapa banyak gen yang bekerja bersama.
Genetika melihat DNA hanya sebagai informasi, mencari pola dalam data, menyelidiki hubungan antara gen dan penampilan fisik. Di sisi lain, Genomics melihat genom sebagai mesin dan mencoba memahami bagaimana bagian-bagiannya bekerja sama.
Ilmu Data Genom
Ilmu Data Genomic menerapkan metode seperti statistik dan pembelajaran mesin yang ditemukan dalam ilmu data untuk masalah genom.
Berkat pengurutan generasi berikutnya, kami dapat mengurutkan genom lebih cepat, lebih murah, dan lebih berhasil. Misalnya, Proyek Genom Manusia dilakukan dengan biaya $2,7 miliar, dan hari ini Anda dapat mengurutkan genom Anda seharga $1000. Untuk alasan ini, petabyte data genom dapat ditemukan di internet.
Organisme hidup lebih kompleks daripada mesin apa pun yang pernah diproduksi manusia. Memecahkan kompleksitas ini berada di luar algoritma klasik atau pemahaman manusia. Sebagian besar penyakit genetik dan kanker disebabkan oleh interaksi lebih dari satu gen dan mengandung variasi genetik.
Salah satu senjata paling ampuh untuk menganalisis data titik data dan sangat kompleks adalah Deep Learning, karena metode klasik mengasumsikan hubungan linier antara gen, padahal tidak demikian.
Dengan Ilmu Data Genomic, studi obat yang dipersonalisasi dapat dipercepat, atau jika Anda bosan, Anda dapat membuat versi 3D wajah mereka dari genom mereka untuk mendeteksi orang yang telah membuang rokok atau permen karet ke jalanan.
Hidup dan DNA
Dari bakteri hingga paus, kehidupan bekerja dengan prinsip yang sama. Semua makhluk hidup dihubungkan bersama dalam pohon kehidupan dan kemungkinan besar diturunkan dari satu nenek moyang yang sama.
DNA merupakan polimer panjang yang terdiri dari 4 basa (A, T, G, C). Hampir semua informasi tentang cara membangun organisme disimpan di sini.
Informasi ini sendiri dan bagaimana prosesnya (epigenetik) berubah seiring waktu.
DNA dapat membawa informasi dalam kombinasi yang hampir tak terbatas. Kode untuk orang yang tidak pernah lahir atau untuk makhluk baru yang tidak pernah muncul sedang menunggu untuk ditemukan di ruang ini.
Dogma Sentral
Jika DNA adalah perangkat lunak, protein adalah perangkat keras yang paling penting. Protein adalah mesin kecil yang melakukan sebagian besar pekerjaan di dalam sel. Sebuah molekul yang disebut mRNA diperlukan ketika mengubah informasi dalam DNA menjadi protein. MRNA pergi ke Ribosom, dan, menurut informasi yang dikandungnya, asam amino digabungkan, dan protein disintesis. Ribosom adalah printer 3D organik.
Runtuhnya Dogma
Sekarang mari kita periksa bagaimana genom bekerja.
DNA eukariotik melilit protein yang disebut histon agar muat di dalam sel, bagian yang padat tidak dapat dibaca, dan daerah yang termetilasi sulit dibaca. Mekanisme yang mengatur kapan DNA harus dibuka tidak sepenuhnya dipahami. Tidak ada aliran informasi searah dari DNA ke protein. Protein juga dapat bertindak sebagai regulator dengan mengikat DNA. mRNA membawa informasi tentang protein mana yang sedang disintesis, tetapi tidak tahu kapan harus disintesis. Faktor transkripsi berperan di sini. Faktor transkripsi mengikat titik-titik tertentu dalam DNA dan mengatur ekspresi gen yang terletak di dekatnya. miRNA, siRNA, Riboswitch juga dapat berpartisipasi dalam tugas pengeditan.
Catatan: Tidak semua mekanisme pengeditan dalam genom dipahami, dan prosesnya lebih kompleks daripada yang dijelaskan di sini.
Memprediksi Pengikatan Faktor Transkripsi
Kami menemukan bahwa sel itu kompleks dan menantang untuk digunakan dengan metode klasik sehingga kami akan mempraktikkan teknik pembelajaran yang mendalam. Kami akan menggunakan garis sel HepG2 dan faktor Transkripsi JunD sebagai data.
HepG2 adalah garis sel abadi yang berasal dari jaringan hati seorang anak Afrika-Amerika berusia 15 tahun. Faktor Transkripsi JunD yang dikodekan oleh gen JUND. Itu dapat menurunkan atau mengaktifkan gen lain.
Kami memilih Kromosom ke-22 sehingga data genom dapat diproses. Kromosom ini mengandung sekitar 50 juta pasangan basa. Ada sekitar 3 miliar pasangan basa pada manusia. Kromosom terbesar adalah yang ke-1, dan yang terkecil adalah yang ke-22.
Data genom disimpan dalam format FASTA atau FASTQ. Data akan terlihat seperti baris buku.
>chr22 NNNNNNNNNNNNNNNNNNNNNNNNN TCCCAAATTGTGGAAGGAATGTACATTTGAC
Di sini kita melihat urutan basa yang terkandung dalam satu untai DNA. Kita bisa bertanya apa yang dilakukan simbol “N” dalam DNA. Ini berarti bahwa tidak dapat diputuskan basis mana yang dibaca dalam proses pengurutan.
Selanjutnya, kita perlu mengubah informasi genom ke dalam format matematika yang dapat kita gunakan. Seperti yang kita lihat, data kita terdiri dari bagian A, T, G, C, dan N. Kita dapat mengekspresikan bagian-bagian ini dengan pengkodean One-hot. Misalnya A:[1,0,0,0] atau G:[0, 0,1,0] dan N:[0.25,0.25,0.25,0.25] dapat diwakili.
[[1., 0., 0., 0.],
[1., 0., 0., 0.],
[0., 1., 0., 0.]
[0., 0., 1., 0.],
[0., 0., 0., 1.]]== [“AATGC”]
Setelah DNA one-hot dikodekan, kita bisa mulai berlatih. Data pelatihan kami terdiri dari 101 basis dan apakah faktor transkripsi terikat pada urutan ini. Misalnya, jika ada 2000 basis, kita akan memiliki 20 baris. Setelah titik ini, masalahnya berubah menjadi pembelajaran yang diawasi.
x . kami[0] == [[1., 0., 0., 0.],
[1., 0., 0., 0.],
[0., 1., 0., 0.]
[0., 0., 1., 0.],
[0., 0., 0., 1.]].. y kami[0] == 1
Kita dapat menggunakan banyak model untuk menemukan hubungan antara x dan y. Untuk contoh ini kita akan menggunakan CNN.
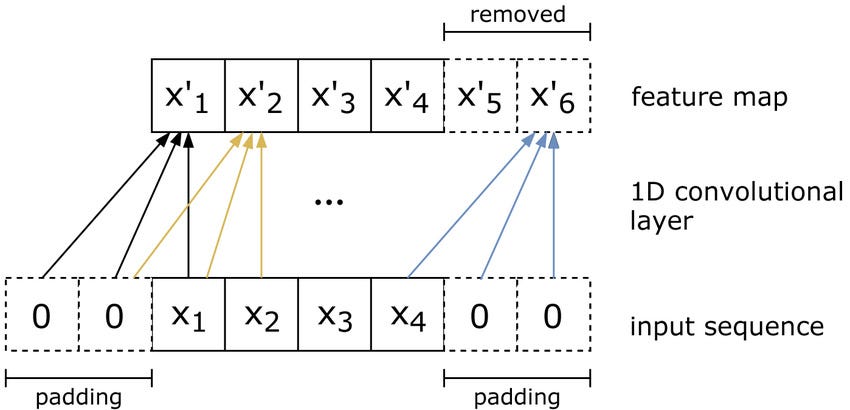 Dari https://www.researchgate.net/figure/Causal-convolution-operation-in-a-1D-convolutional-layer-with-k-3-kernel-size-Input_fig1_337703712
Dari https://www.researchgate.net/figure/Causal-convolution-operation-in-a-1D-convolutional-layer-with-k-3-kernel-size-Input_fig1_337703712
Karena DNA adalah string, itu adalah satu dimensi. Kita dapat menggunakan arsitektur yang berbeda. Salah satu arsitektur yang paling berguna untuk menemukan pola dalam data 1D adalah Convolutional Neural Networks. Mereka umumnya digunakan pada gambar (informasi 2D) dan CNN 1D dapat digunakan untuk memproses teks.
CNN 2D mengekstrak fitur dari gambar, mempelajari tentang tepi, simpul, perubahan warna, dan pola yang lebih kompleks. Demikian pula, kita dapat mempelajari filter yang dapat mengekstrak fitur dari data teks. Setelah model kami dilatih, kami dapat menghitung probabilitas bahwa protein JunD akan mengikat fragmen DNA sepanjang 101 basa.
Menghasilkan Hasil yang Lebih Realistis
Ada banyak faktor dalam pengikatan protein JunD ke DNA: aksesibilitas, metilasi, bentuk, keberadaan molekul lain.
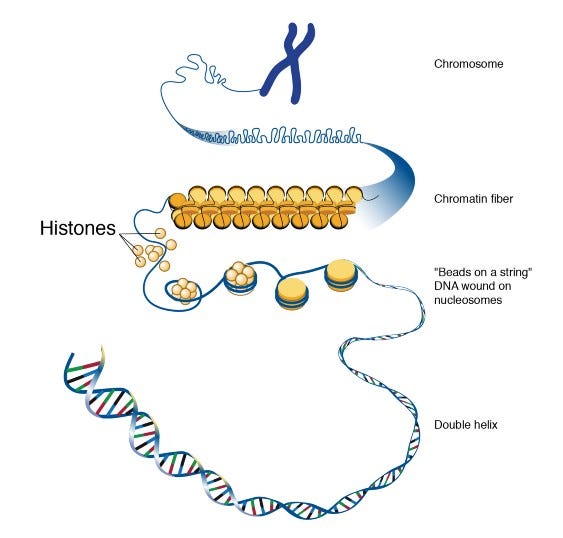 Dari https://www.scinexx.de/dossierartikel/auch-die-verpackung-machts/
Dari https://www.scinexx.de/dossierartikel/auch-die-verpackung-machts/
Aksesibilitas kromatin: Menentukan seberapa mudah akses DNA ke molekul dari luar. Ketika DNA melilit histon dengan erat, Faktor Transkripsi atau molekul lain tidak dapat diakses. Demikian pula, gen yang akan dibungkam dapat dikemas.
Aksesibilitas suatu wilayah tidaklah konstan. Itu berubah seiring waktu. Jika kami menambahkan informasi aksesibilitas kromatin ke kumpulan data kami, kami dapat membuat prediksi yang lebih realistis.
Kesimpulan dan Contoh Kode
Kompleksitas biologi berada di luar pemahaman manusia. Inilah sebabnya mengapa kita membutuhkan pembelajaran mesin untuk memahami dan meningkatkan diri kita sendiri.
Ketika genom diurutkan, para ilmuwan mengira mereka telah memecahkan semua rahasia, tetapi mereka hanya menggores permukaan. Alat pengeditan genom seperti CRISPR juga tidak menyelesaikan masalah kami. Kami tidak dapat mengedit tanpa memprediksi konsekuensi dari perubahan genetik. Mengungkap rahasia genom, jika bukan dengan cara yang tidak dapat dijelaskan, akan memberikan kesempatan untuk merancang makhluk hidup baru untuk membasmi banyak penyakit.
Data dan kode sampel dapat ditemukan di akun GitHub saya.
GitHub – OmerOzgur271/Genomic-Datascience
Ilmu Data awalnya diterbitkan di Towards AI on Medium, di mana orang-orang melanjutkan percakapan dengan menyoroti dan menanggapi cerita ini.
Diterbitkan melalui Menuju AI

Lenovo IdeaCentre AIO 3, Komputer All-in-One 24″, Prosesor Mobile AMD Ryzen 3 4300U, Grafis Terintegrasi, 8GB DDR4, SSD Nama M.2 256GB, Drive DVD RW, Windows 10, F0EW005TUS, Business Black
$549,99 (per 12 November 2021 16:22 GMT -05:00 – Info lebih lanjutHarga dan ketersediaan produk akurat pada tanggal/waktu yang ditunjukkan dan dapat berubah. Informasi harga dan ketersediaan apa pun yang ditampilkan di [relevant Amazon Site(s), as applicable] pada saat pembelian akan berlaku untuk pembelian produk ini. %site_host% adalah peserta dalam Program Associates Amazon Services LLC, program periklanan afiliasi yang dirancang untuk menyediakan sarana bagi situs untuk mendapatkan biaya komisi dengan mengiklankan dan menautkan ke situs web berikut. %associates_list%)